

Have you ever come across a piece of "clever" Javascript code that causes you to slow down and concentrate a little harder in order to digest it?
"Prefer readability over premature optimization" is a popular developer mantra, but the mantra also implies that the two are mutually exclusive. Does this assumption actually hold true when we are dealing with hard-to-parse one-liners?
Here's an example of a "clever" piece of code, a one-line solution to the FizzBuzz problem (taken from this medium post):
function oneLineFizBuzz (n) {
return ((n % 3 ? '' : 'fizz') + (n % 5 ? '' : 'buzz') || n);
}Sure, you have to squint a little and think through the use case where n is divisible by both 3 and 5, and you also have to remember that an empty string evaluates to a falsy value in Javascript, but at least it's fast right?
For comparison's sake, let's also create a much more straightforward version of the FizzBuzz solution:
function clearFizzBuzz (n) {
let result;
const div3 = n % 3 === 0;
const div5 = n % 5 === 0;
if (div3 && div5) {
result = 'fizzbuzz';
} else if (div3) {
result = 'fizz';
} else if (div5) {
result = 'buzz';
} else {
result = n;
}
return result;
}The second solution – while argueably contrived and longer than it needs to be – is easier to read and reason about. But is it slower than the one-line version? And if so, by how much?
By the end of the post, you'll see that because most of our JS code runs on highly optimized engines, performance and readability are not mortal enemies. In fact, readable Javascript is frequently the same as performant Javascript.
Benchmarking Our Functions
Looking at our two functions, the clear version contains two more constant assignments (div3, div5) and one more branching operation (div3&&div5). It should in theory be slower.
To make sure, let's run some experiments using the benchmark file from Surma's Is WebAssembly magic performance pixie dust? post (gist). We'll run each function for integers from 1 to 10e5 for 10 iterations and average the results. We'll also run 10 iterations before recording results, allowing the V8 engine to warm up and optimize the two functions:
const ITERATIONS = 10;
const oneLineResults = benchmark({
run() {
for (let i = 1; i < 10e5; i++) {
oneLineFizBuzz(i);
}
},
numWarmup: 10,
numIterations: ITERATIONS
});
print('one line version result:', oneLineResults.average);
Here's our result running the testing code with NodeJS:
one line version result: 4.6
clear version result: 2.7The more verbose version is significantly faster. Huh, what gives?
V8 Bytecode
To get a better understanding of why our clever one-liner FizzBuzz solution is slower, we need to take a look at how V8 works. V8 is the Javascript engine that powers NodeJS, you can directly download a binary version of the engine either via JSVU instead of compiling locally.
The results below are from v8-debug-10.4.132 on my local Linux 64-bit system.
Here's a diagram of how V8 processes our Javascript source code:
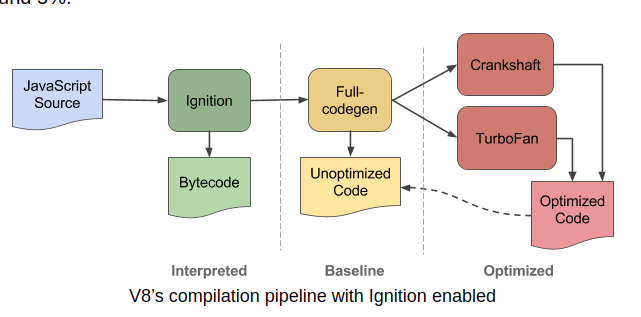
Note: this diagram is out of date, the V8 engine v10.4 no longer uses Crankshaft and instead has two additional optimizers before TurboFan – Sparkplug and Maglev.
On engine start, V8 first parses the JS code into its AST, then the Ignition interpreter translates the AST into platform-independent V8 Bytecode before passing it on to additional optimizing compilers. Its the optimizers' job to turn the platform-independent bytecode into platform-specific machine optimized code.
Here's what the Bytecode of our one-liner FizzBuzz function looks like:
[generated bytecode for function: oneLineFizBuzz (0x12ea00253ad9 <SharedFunctionInfo oneLineFizBuzz>)]
Bytecode length: 35
Parameter count 2
Register count 1
Frame size 8
Bytecode age: 0
0x12ea00253d76 @ 0 : 0b 03 Ldar a0
0x12ea00253d78 @ 2 : 49 03 01 ModSmi [3], [1]
0x12ea00253d7b @ 5 : 97 06 JumpIfToBooleanFalse [6] (0x12ea00253d81 @ 11)
0x12ea00253d7d @ 7 : 13 00 LdaConstant [0]
...
0x12ea00253d94 @ 30 : 96 04 JumpIfToBooleanTrue [4] (0x12ea00253d98 @ 34)
0x12ea00253d96 @ 32 : 0b 03 Ldar a0
0x12ea00253d98 @ 34 : a9 Return You can generate function bytecode by running the debug-v8 engine with the flag --print-bytecode.
And as suspected, the Bytecode of our clearFizzBuzz the function is longer than its one-liner counterpart (note the length of 63 vs 35 for oneLineFizzBuzz).
[generated bytecode for function: clearFizzBuzz (0x12ea00253b11 <SharedFunctionInfo clearFizzBuzz>)]
Bytecode length: 63
Parameter count 2
Register count 4
Frame size 32
Bytecode age: 0
0x12ea00253e1e @ 0 : 0e LdaUndefined
0x12ea00253e1f @ 1 : c4 Star0
...In fact, if we run our benchmark test without using any of V8's optimizers, the one-liner version is indeed faster – though not by much.
one line version result: 3948.4
clear version result: 4085.8V8 Optimized Javascript
The most surprising thing about our previous result is not how similar the function performances are. It's the fact that TurboFan optimization gave us a 1000-fold increase in execution speed.
As mentioned earlier, once a piece of JS code is invoked multiple times, V8's TurboFan optimizer kicks in and produces an optimized version of our functions. You can view the optimized code via V8's --print-opt-code flag.
Here are the first few lines of our optimized clear function:
optimization_id = 0
source_position = 135
kind = TURBOFAN
name = clearFizzBuzz
stack_slots = 6
compiler = turbofan
address = 0x7f88c0084001
Instructions (size = 480)
0x7f88c0084040 0 488d1df9ffffff REX.W leaq rbx,[rip+0xfffffff9]
...versus our one-line function:
optimization_id = 1
source_position = 31
kind = TURBOFAN
name = oneLineFizBuzz
stack_slots = 6
compiler = turbofan
address = 0x7f88c0084241
Instructions (size = 592)
0x7f88c0084280 0 488d1df9ffffff REX.W leaq rbx,[rip+0xfffffff9]
...The important bit here is the instruction size. Our one-liner FizzBuzz solution has an instruction size of 592 while the readable variation is only 480 instructions long.
While both our intuition and the V8 bytecode informed us the one-liner function should be faster, the optimized TurboFan result is the reverse.
While I did not perform additional testing to confirm exactly why our 'clever' FizzBuzz solution is slower in practice. Though I suspect the culprit is the string concatenation that must be done on every iteration that slows it down.
Takeaways
I hope this post has convinced you that code readability and performance are not mutually exclusive — at least not in the case of Javascript running on a highly optimized compiler.
So next time you see a piece of clever code in an MR that makes you pause and squint, point out that it can be written more clearly – and potentially without any performance penalties.
And next time you are tempted to write something clever and super concise, consider rewriting it for readability and for performance.
Thanks for reading this far. As always, if you found this post helpful, please share it with others. You may also be interested in learning about Troubleshooting Javascript memory leaks or How to measure web performance with the Navigation TIming API. You can also subscribe to email updates using the form below.
Additional Readings
- Franziska Hinkelmann's excellent Understanding V8's Bytecode
- Matt Zeunert's Compiling V8 and Viewing the assembly code it generates
- V8 Blog's Sparkplug — a non-optimizing JavaScript compiler, Firing up the Ignition interpreter
- An Overview of the TurboFan Compiler